Reading and Writing team - CNS Lab
We work on problems related to reading and writing

We work on problems related to reading and writing
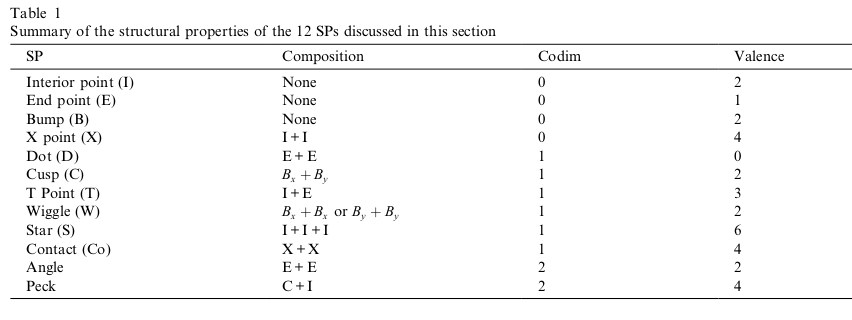
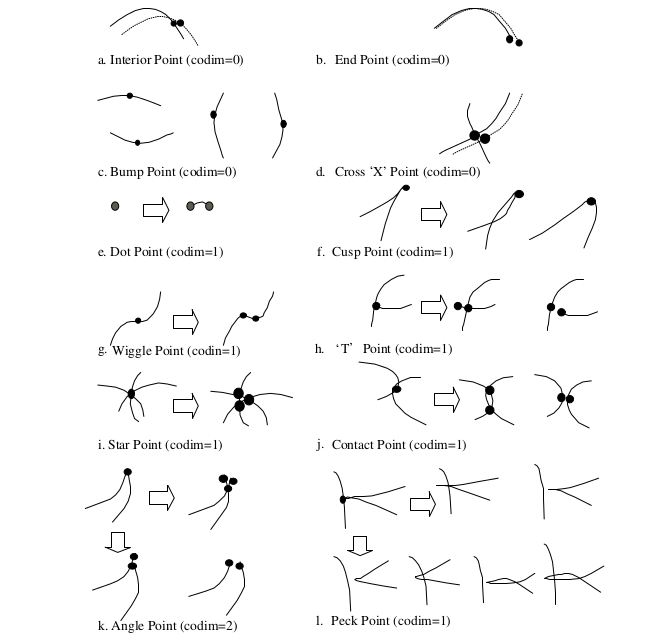 Illustrations of elementary shape points
Illustrations of elementary shape points
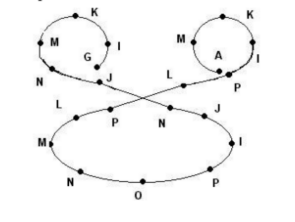
 Graph representations of handwritten uppercase English alphabets
Graph representations of handwritten uppercase English alphabets
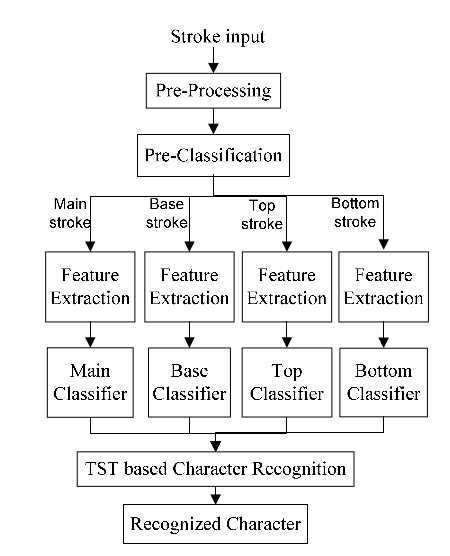
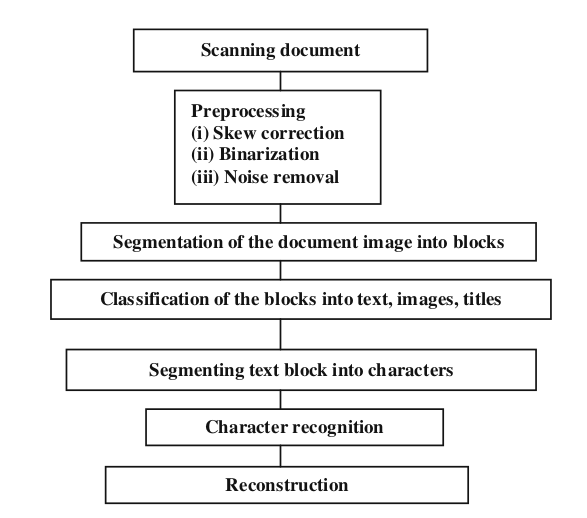
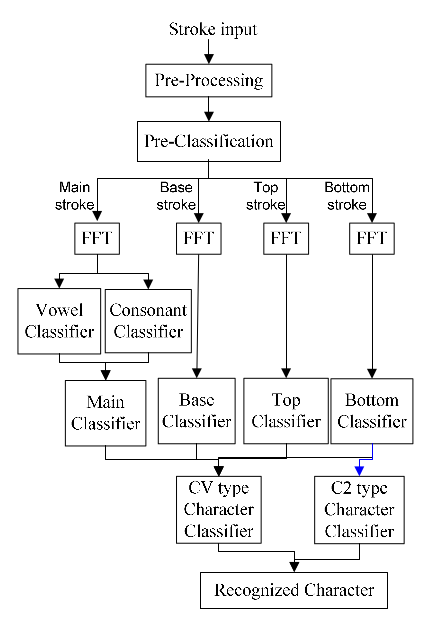 Flow chart diagram of different stages in two schemas
Flow chart diagram of different stages in two schemas
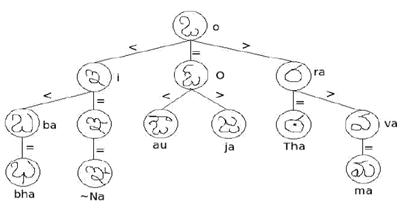 Ternary Search Tree representation of Telugu Character
Ternary Search Tree representation of Telugu Character
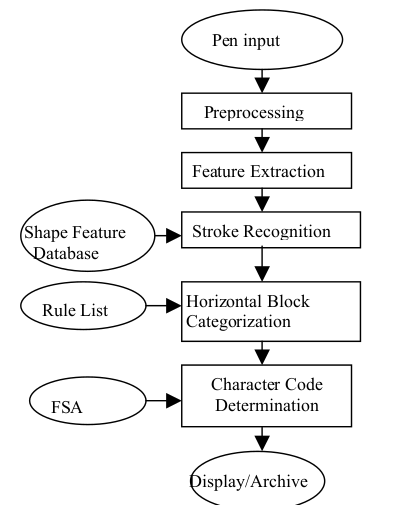 Flow chart diagram of different stages
Flow chart diagram of different stages
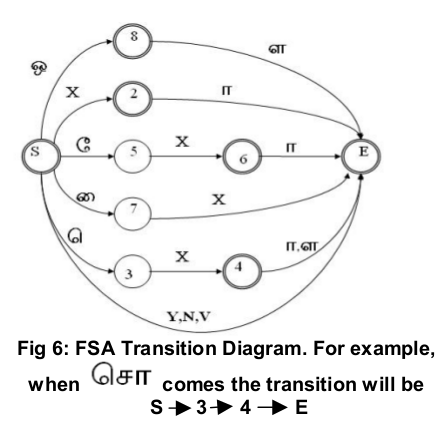
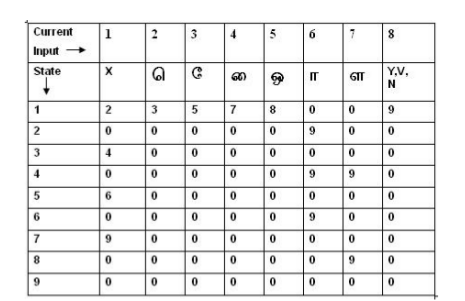 Transition table of Finite State Machine
Transition table of Finite State Machine
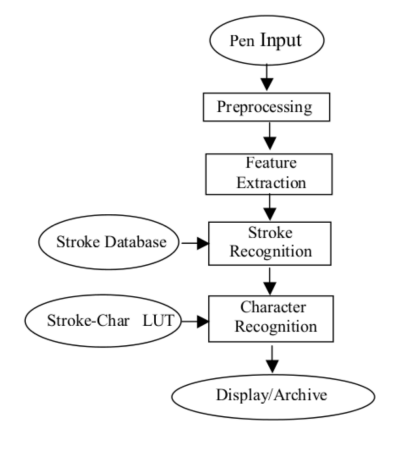 Schematic representation of the character recognition model
Schematic representation of the character recognition model
 Representation of Malayalam character 'R' (as in Rishi), as a string of shape features
Representation of Malayalam character 'R' (as in Rishi), as a string of shape features

 A sample handwritten Malayalam text and its recognized output in LEKHAK
A sample handwritten Malayalam text and its recognized output in LEKHAK
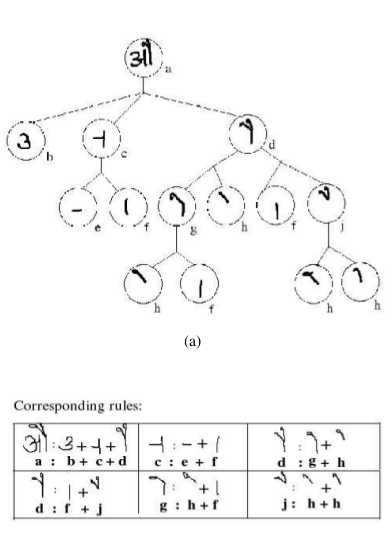 Identifying rules for writing the character /au/ in Devanagari script
Identifying rules for writing the character /au/ in Devanagari script

 Schematic representation of steps involved
Schematic representation of steps involved

 Text area segmentation from Tamil magazine page
Text area segmentation from Tamil magazine page
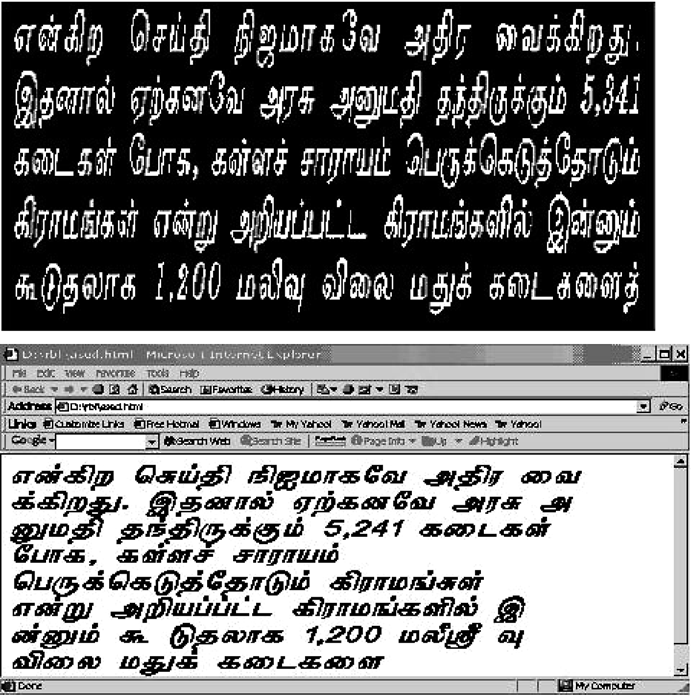 Recognition of text
Recognition of text
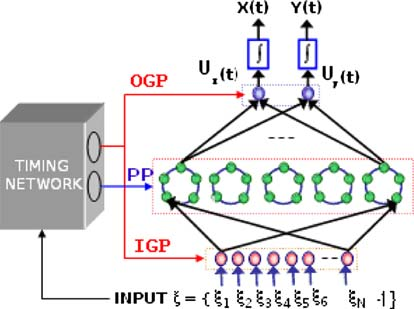 Network architecture
Network architecture
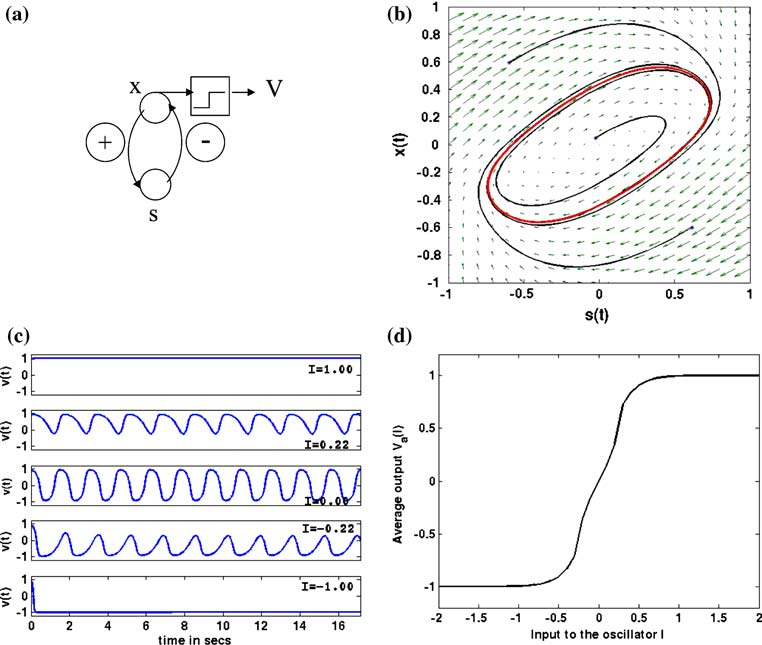 Schematic depicting of the dynamics of a single neural oscillator
Schematic depicting of the dynamics of a single neural oscillator
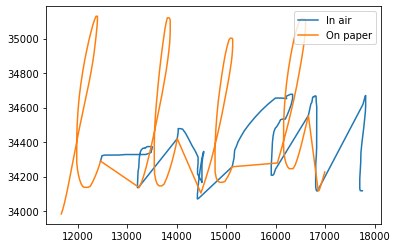
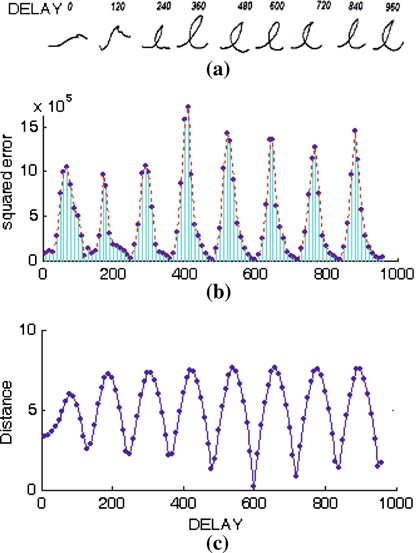 Post-preparatory delay and its influence on error and stroke generation
Post-preparatory delay and its influence on error and stroke generation
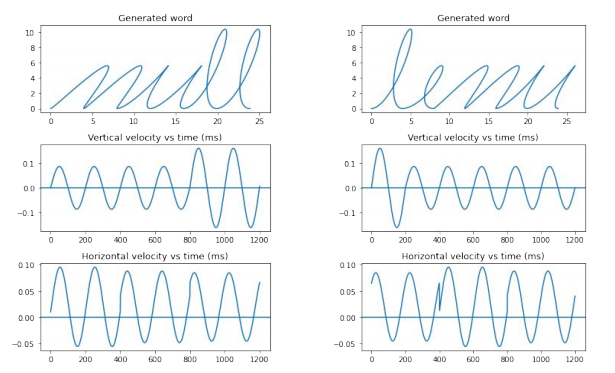
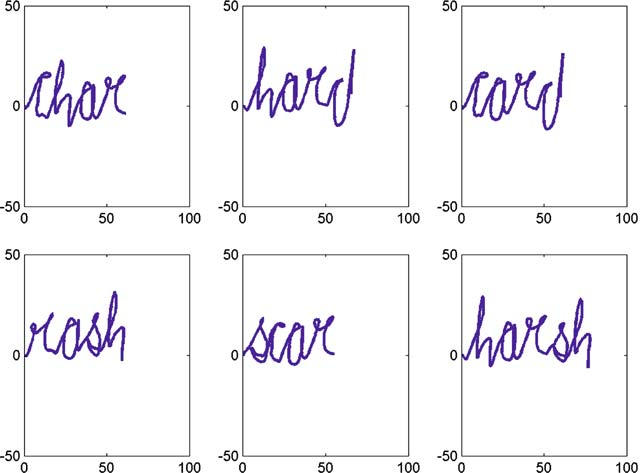 Four and five-letter words produced by the handwriting network
Four and five-letter words produced by the handwriting network
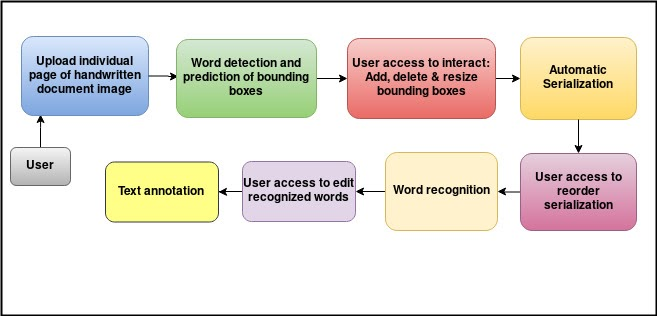 Different stages of the pipeline
Different stages of the pipeline
 Adjusting bounding boxes
Adjusting bounding boxes
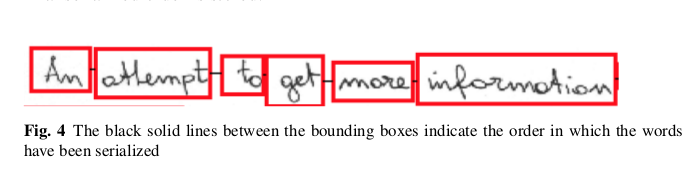


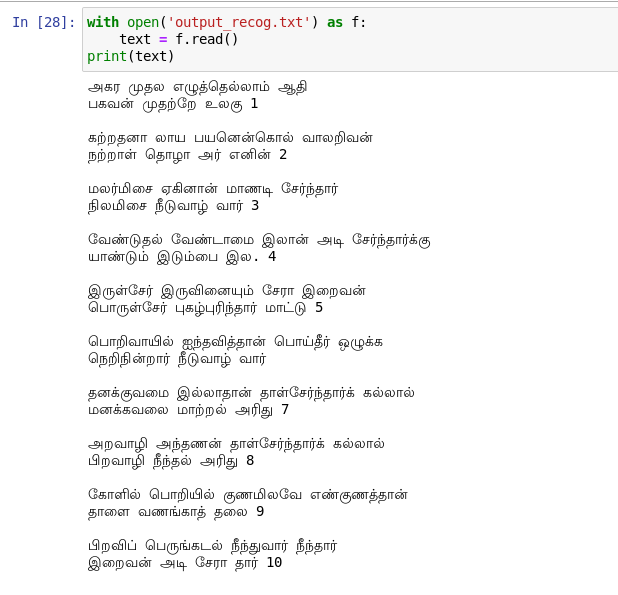 Model output for a given sample page from Thirukkural Urai book
Model output for a given sample page from Thirukkural Urai book
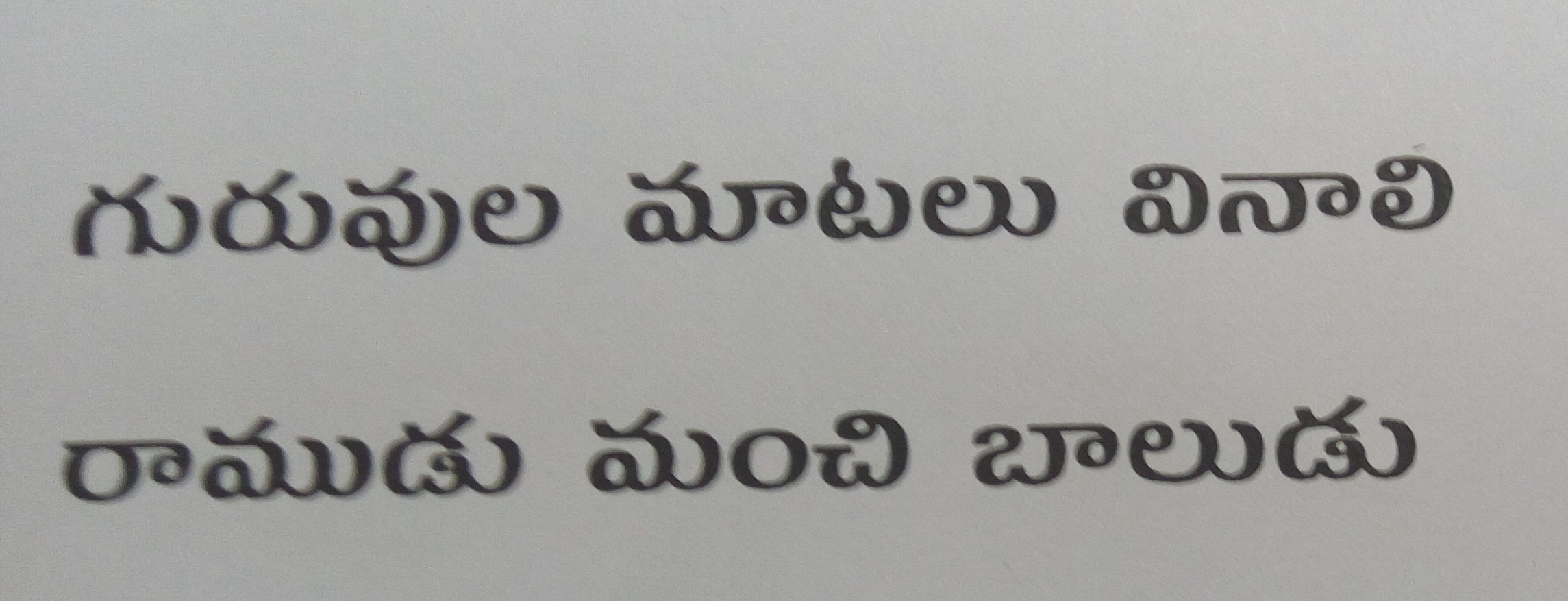
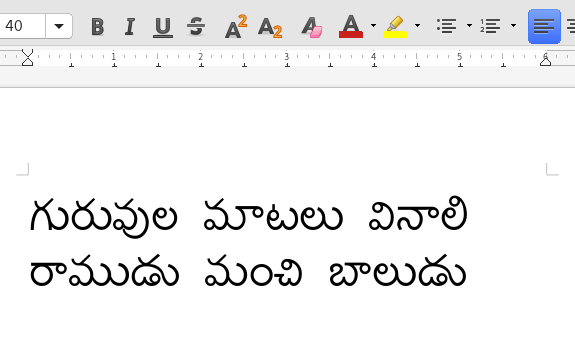 Model output for a given sample input
Model output for a given sample input
 Text paragraph detection in Telugu daily
Text paragraph detection in Telugu daily
 Word level segmentation
Word level segmentation